https://habr.com/ru/company/skillfactory/blog/510688/. what is p-value?
http://www.stochasticlifestyle.com/the-essential-tools-of-scientific-machine-learning-scientific-ml/
https://habr.com/ru/post/475552/ Блиц-проверка алгоритмов машинного обучения: скорми свой набор данных библиотеке scikit-learn
https://habr.com/ru/post/460557/
https://habr.com/ru/post/462961/ . ML Digest
http://themlbook.com/wiki/doku.php
https://vas3k.ru/blog/machine_learning/
https://ml-cheatsheet.readthedocs.io/
https://github.com/danielhanchen/hyperlearn/blob/master/Modern%20Big%20Data%20Algorithms%20(Lower%20quality%20PDF).pdf
https://habr.com/ru/post/453290/ Data Science Digest
https://github.com/kmario23/deep-learning-drizzle
https://github.com/trekhleb/homemade-machine-learning . HomeMade ML using Jupiter Notebook
https://habr.com/ru/post/449260/ . AutoML
https://github.com/mljar/mljar-supervised . AutoML
https://ai.googleblog.com/2019/05/an-end-to-end-automl-solution-for.html . AutoML
https://news.ycombinator.com/item?id=19712465 . ML workflow
https://www.textbook.ds100.org/ Introduction to datascience
https://github.com/machinelearningmindset/machine-learning-course
https://blog.floydhub.com/introduction-to-anomaly-detection-in-python/
https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html Loss function
https://gombru.github.io/2018/05/23/cross_entropy_loss/
https://residentmario.github.io/machine-learning-notes/kernels.html
https://aws.amazon.com/training/learning-paths/machine-learning/
https://www.youtube.com/playlist?list=PLl8OlHZGYOQ7bkVbuRthEsaLr7bONzbXS . CORNELL CS4780
https://news.ycombinator.com/item?id=20570025 . ML Books
https://github.com/r0f1/datascience a list of links
https://deepmind.com/blog/unsupervised-learning/
https://www.octavian.ai/machine-learning-on-graphs-course
https://jinchuika.com/en/post/1-preprocessing-part-1/ . Preprocessing
https://skymind.ai/wiki/
https://github.com/clone95/Machine-Learning-Study-Path/blob/master/README.md
In math terms, an operation F is linear if scaling inputs scales the output, and adding inputs adds the outputs:
F(ax) = a * F(x)
F(x + y) = F(x) + F(y)
Linear Models
https://habrahabr.ru/company/ods/blog/323890/ Linear models
https://medium.freecodecamp.org/learn-how-to-improve-your-linear-models-8294bfa8a731
http://www.jmlr.org/papers/volume18/17-468/17-468.pdf . Automatic Differentiation
Statistical tests:
https://lindeloev.github.io/tests-as-linear/
https://www.youtube.com/watch?v=enpPFqcIFj8&list=PLlb7e2G7aSpRb95_Wi7lZ-zA6fOjV3_l7 .
Анализ данных на Python в примерах и задачах
https://distill.pub/2019/visual-exploration-gaussian-processes/ . Gaussian process
https://blog.finxter.com/python-linear-regression-1-liner/
from sklearn.linear_model import LinearRegression
import numpy as np
## Data (Apple stock prices)
apple = np.array([155, 156, 157])
n = len(apple)
## One-liner
model = LinearRegression().fit(np.arange(n).reshape((n,1)), apple)
print(model.predict([[3],[4]]))
## Result
print(model.coef_)
# [1.]
print(model.intercept_)
# 155.0
Linear regression can be applied to model non-linear relationship between input and response.
This can be done by replacing the input x with some nonlinear function φ(x).
Note that doing so preserves the linearity as a function of the parame- ters w,
https://habr.com/ru/company/mailru/blog/513842/. different types of regression
https://www.youtube.com/watch?v=68ABAU_V8qI . Linear models
https://github.com/Yorko/mlcourse.ai
https://medium.com/@vimarshk . ML interview
https://github.com/trekhleb/homemade-machine-learning
https://jalammar.github.io/ visuaslization ML cocepts
http://blog.christianperone.com/2019/01/a-sane-introduction-to-maximum-likelihood-estimation-mle-and-maximum-a-posteriori-map/
Logistic regression
https://towardsdatascience.com/logistic-regression-b0af09cdb8ad
https://habr.com/ru/post/485872/
https://realpython.com/logistic-regression-python/
https://towardsdatascience.com/10-gradient-descent-optimisation-algorithms-86989510b5e9]
https://github.com/turingbirds/gradient_descent/blob/master/gradient_descent.ipynb
https://raiboso.me/backpropagation-demo/
https://www.reddit.com/r/learnmachinelearning/comments/ax6ep5/machine_learning_git_codebook_case_study_of/
https://hackernoon.com/tackle-bias-and-other-problems-solutions-in-machine-learning-models-f4274c5fe538
https://erikbern.com/2018/10/08/the-hackers-guide-to-uncertainty-estimates.html
https://brohrer.github.io/how_modeling_works_1.html
https://github.com/zekelabs/data-science-complete-tutorial
https://dyakonov.org/
https://github.com/AntonioErdeljac/Google-Machine-Learning-Course-Notes
https://github.com/robertmartin8/udemyML . code and notes for Kirill Eremenko's Machine Learning course
https://habr.com/ru/company/singularis/blog/440026/ . Real Kaggle project
Books
http://themlbook.com . The 100 pages ML book (Andrij Burkov)
https://github.com/jakevdp/PythonDataScienceHandbook
https://news.ycombinator.com/item?id=19296031
https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/ e-book
https://play.google.com/store/books/details/Николенко_Сергей_Игоревич_Глубокое_обучение?id=Zi48DwAAQBAJ
https://john.specpal.science/deepvision/
https://jakevdp.github.io/PythonDataScienceHandbook/ BOOK ONLINE
http://www.cs.huji.ac.il/~shais/UnderstandingMachineLearning/ Book
https://github.com/zackchase/mxnet-the-straight-dope e-book
https://github.com/rasbt/python-machine-learning-book-2nd-edition ML book with python code
https://christophm.github.io/interpretable-ml-book/ . Book
http://www.cs-114.org/wp-content/uploads/2015/01/Elements_of_Information_Theory_Elements.pdf
https://www.microsoft.com/en-us/research/publication/pattern-recognition-machine-learning/ Bishop Book
ISLR book and videos:
http://auapps.american.edu/alberto/www/analytics/ISLRLectures.html
https://github.com/JWarmenhoven/ISLR-python/tree/master/Notebooks
https://mml-book.github.io/
http://www.inference.phy.cam.ac.uk/itprnn/book.pdf David MacKay. Information Theory, Inference and Learning Algorithms
http://mbmlbook.com/
https://universalflowuniversity.com/ulibrary/?drawer1=Computer%20Programming*Neural%20Networks%20and%20Deep%20Learning
https://github.com/joelgrus/data-science-from-scratch - Code from book "Data science from scratch"
https://news.ycombinator.com/item?id=18201986
Metahevristics
https://proplot.readthedocs.io/en/stable/
https://habr.com/ru/post/688820/
http://www2.cscamm.umd.edu/publications/BookChapter_CS-09-13.pdf
https://cs.gmu.edu/~sean/book/metaheuristics/Essentials.pdf
https://medium.com/huggingface/from-zero-to-research-an-introduction-to-meta-learning-8e16e677f78a MetaLearning
https://sgfin.github.io/learning-resources/
https://see.stanford.edu/Course/CS229
https://github.com/danielhanchen/hyperlearn/blob/master/Modern%20Big%20Data%20Algorithms.pdf
https://www.coursera.org/promo/NEXTExtended
https://habr.com/company/tssolution/blog/423783/ Splunk
SageMaker:
https://towardsdatascience.com/building-fully-custom-machine-learning-models-on-aws-sagemaker-a-practical-guide-c30df3895ef7
Deployment
https://towardsdatascience.com/create-a-complete-machine-learning-web-application-using-react-and-flask-859340bddb33
https://www.inovex.de/blog/machine-learning-model-management/
https://towardsdatascience.com/deploying-a-machine-learning-model-as-a-rest-api-4a03b865c166 . Flask Rest API for model
https://heartbeat.fritz.ai/brilliant-beginners-guide-to-model-deployment-133e158f6717
https://towardsdatascience.com/deploying-a-keras-deep-learning-model-as-a-web-application-in-p-fc0f2354a7ff
https://habr.com/ru/company/otus/blog/442918/
https://www.dataquest.io/blog/learning-curves-machine-learning/
https://arxiv.org/abs/1809.10756 . probabilistic programming
https://github.com/Avik-Jain/100-Days-Of-ML-Code
https://github.com/seddonr/Ng_ML . Ng Cousera implemented in Python
https://www.youtube.com/channel/UCsBKTrp45lTfHa_p49I2AEQ Brandon Rohrer
Automatic differentiation
https://github.com/tensorflow/swift/blob/master/docs/AutomaticDifferentiation.md
https://www.sanyamkapoor.com/machine-learning/autograd-magic/ . Automatic Differentiation and back propagation
https://aws.amazon.com/training/learning-paths/machine-learning/
http://www.fast.ai/2018/09/26/ml-launch/ . Online Course
Boosting and bagging
https://habr.com/ru/company/piter/blog/488362/
https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d
https://habr.com/ru/company/piter/blog/445780/
https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
Ансамблевый метод — это метод, который совмещает множество слабых учеников,
которые основаны на одном и том же обучающемся алгоритме, с целью создания (более сильного) ученика,
чья результативность лучше,
чем у любого из отдельно взятых учеников. Ансамблевые методы помогают уменьшить смещение и/или дисперсию.
бустирование совершенно отличается от бэггирования:
- Подгонка индивидуальных классификаторов выполняется последовательно.
- Слаборезультативные классификаторы отклоняются.
- На каждой итерации наблюдения взвешиваются по-разному.
XGBoost
https://habr.com/ru/company/mailru/blog/438560/
https://habr.com/ru/company/mailru/blog/438562/
https://saru.science/tech/2018/02/15/kl-divergence-explanation.html
Kullback-Leibler divergence
https://news.ycombinator.com/item?id=17916981
https://www.coursera.org/learn/machine-learning-projects/
https://www.youtube.com/user/PyDataTV/videos
https://bloomberg.github.io/foml/#lectures
https://appliedmachinelearning.blog/
https://ml-cheatsheet.readthedocs.io/en/latest/
https://github.com/afshinea/stanford-cs-229-machine-learning/blob/master/super-cheatsheet-machine-learning.pdf
https://stanford.edu/~shervine/teaching/cs-229/
http://anotherdatum.com/index2.html
ML BOOK with code:
https://arxiv.org/pdf/1803.08823
http://physics.bu.edu/~pankajm/ML-Notebooks/NotebooksforMLReview.zip - jupyter notebooks (zip)
X-means http://docs.splunk.com/Documentation/MLApp/3.4.0/User/Algorithms#X-means
Алгоритм кластеризации X-means представляет собой расширенный алгоритм k-means,
который автоматически определяет количество кластеров на основе информационного байесовского критерия (BIC).
Этот алгоритм удобно использовать, когда нет предварительной информации о числе кластеров,
на которые эти данные могут быть разделены.
RobustScaler http://docs.splunk.com/Documentation/MLApp/3.4.0/User/Algorithms#RobustScaler
Это алгоритм предварительной обработки данных. По применению схож с алгоритмом StandardScaler,
который преобразует данные так, что для каждого признака среднее будет равно 0, а дисперсия будет равна 1, в
результате чего все признаки будут иметь один и тот же масштаб.
Однако это масштабирование не гарантирует получение каких-то конкретных минимальных и максимальных значений признаков.
RobustScaler аналогичен StandardScaler в том плане, что в результате его применения признаки будут иметь один и тот же масштаб.
Однако RobustScaler вместо среднего и дисперсии использует медиану и квартили.
Это позволяет RobustScaler игнорировать выбросы или ошибки измерений, которые могут стать проблемой для остальных методов
масштабирования.
Links
https://sandipanweb.wordpress.com/
https://habr.com/company/intel/blog/417809/ . NN architectures for image recognition
https://kite.com/blog/python/data-analysis-visualization-python
https://habr.com/company/nixsolutions/blog/417935/ памятки по искусственному интеллекту
https://thegradient.pub/why-rl-is-flawed/
https://habr.com/post/418249/ . Google VM for ML
https://medium.com/syncedreview/google-ai-chief-jeff-deans-ml-system-architecture-blueprint-a358e53c68a5
https://news.ycombinator.com/item?id=17667705 . ML intro
https://news.ycombinator.com/item?id=17422770 Matrix 101 for ML
https://news.ycombinator.com/item?id=17664084 Math for ML
http://tools.google.com/seedbank/
https://developers.google.com/machine-learning/guides/
https://codequs.com/p/BkaLEq8r4/a-complete-machine-learning-project-walk-through-in-python
https://morioh.com/p/b56ae6b04ffc/a-complete-machine-learning-project-walk-through-in-python
ML from start to end
Open Machine Learning
https://towardsdatascience.com/forecasting-with-python-and-tableau-dd37a218a1e5 . Tableau+ARIMA+Python
https://mlcrunch.blogspot.com/2018/08/dimensionality-reduction-techniques-guide-python.html
https://github.com/Avik-Jain/100-Days-Of-ML-Code
https://sandipanweb.wordpress.com/2018/05/31/8626/
http://ciml.info/
https://news.ycombinator.com/item?id=17214588
http://ods.ai/
https://habrahabr.ru/company/ods/blog/344044/ Open Data Science
https://habrahabr.ru/company/ods/blog/325422/ Открытый курс машинного обучения. Тема 6. Построение и отбор признаков
Part 1
Part 2
Part 3
https://towardsdatascience.com/another-machine-learning-walk-through-and-a-challenge-8fae1e187a64
## Russian translation of 3 links above:
https://habr.com/company/nixsolutions/blog/425253
https://habr.com/company/nixsolutions/blog/425907/
https://habr.com/company/nixsolutions/blog/426771/
https://github.com/esokolov/ml-course-hse (ru)
intrepretable-machine-learning-nfl
https://spandan-madan.github.io/DeepLearningProject/ End to End Implementation
https://spandan-madan.github.io/DeepLearningProject/docs/Deep_Learning_Project-Pytorch.html
https://towardsdatascience.com/visualizing-data-with-pair-plots-in-python-f228cf529166 Pair plots
Markov Chain Monte Carlo
https://towardsdatascience.com/markov-chain-monte-carlo-in-python-44f7e609be98
https://habr.com/ru/company/piter/blog/491268/
https://news.ycombinator.com/item?id=19633212
http://arogozhnikov.github.io/2016/12/19/markov_chain_monte_carlo.html
https://news.ycombinator.com/item?id=15986687 Markov chain Monte-Carlo
http://www.moderndescartes.com/essays/deep_dive_mcts/ monte carlo tree search
https://skymind.ai/wiki/generative-adversarial-network-gan
https://habr.com/post/429276/ Вариационный автокодировщик VAE (автоэнкодер) — это генеративная модель,
которая учится отображать объекты в заданное скрытое пространство.
https://www.youtube.com/watch?v=Lo1rXJdAJ7w C++ ML
https://software.intel.com/en-us/ai-academy Intel AI
https://research.fb.com/the-facebook-field-guide-to-machine-learning-video-series/ FaceBook ML video series
https://medium.com/@deepsystems
https://datamonsters.com/ company
https://eli.thegreenplace.net/2018/minimal-character-based-lstm-implementation/
http://www.wildml.com/
PyTorch
https://habr.com/company/otus/blog/358096/
https://habr.com/company/piter/blog/354912/
https://www.reddit.com/r/Python/comments/878vjb/compute_distance_between_strings_30_algorithms/
https://thomaswdinsmore.com/
https://towardsdatascience.com/data-science-interview-guide-4ee9f5dc7784
https://medium.com/acing-ai/apple-ai-interview-questions-acing-the-ai-interview-803a65b0e795
https://towardsdatascience.com/data-science-and-machine-learning-interview-questions-3f6207cf040b
http://savvastjortjoglou.com/intrepretable-machine-learning-nfl-combine.html
PDF
QnA
My code
Neural Networks and Image Processing
https://towardsdatascience.com/building-prediction-apis-in-python-part-4-decoupling-the-model-and-api-4b5eaf2ed125
Statistics
https://en.wikipedia.org/wiki/Correlation_and_dependence
http://pages.cs.wisc.edu/~tdw/files/cookbook-en.pdf
https://etav.github.io/articles/ida_eda_method.html
http://statistics.zone/
https://h4labs.wordpress.com/2017/12/30/learning-probability-and-statistics/
https://news.ycombinator.com/item?id=18462520 . estimate probability of yet unhappen
Calculating avg and stdev on stream
--------------------------------------
https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance
https://math.stackexchange.com/questions/20593/calculate-variance-from-a-stream-of-sample-values
https://blog.superfeedr.com/streaming-percentiles/
https://www.johndcook.com/blog/standard_deviation/
https://dev.to/nestedsoftware/calculating-a-moving-average-on-streaming-data-5a7k
https://en.wikipedia.org/wiki/Receiver_operating_characteristic ROC curve
https://habrahabr.ru/post/311092/ standard distibutions
https://en.wikipedia.org/wiki/Outlier
https://medium.com/netflix-techblog/rad-outlier-detection-on-big-data-d6b0494371cc
https://en.wikipedia.org/wiki/Maximum_likelihood_estimation
https://en.wikipedia.org/wiki/Precision_and_recall
https://data36.com/statistical-bias-types-explained/
https://data36.com/statistical-bias-types-examples-part2/
Precision is the number of correct positive classifications divided by the total number of positive labels assigned.
precision=true positives / (true positives+false positives)
Recall is the number of correct positive classifications divided by the number of positive instances that should have been identified.
recall=true positives / (true positives+false negatives)
https://en.wikipedia.org/wiki/Quantile
https://www.analyticsvidhya.com/blog/2017/02/basic-probability-data-science-with-examples/
https://en.wikipedia.org/wiki/Simpson%27s_paradox
Bayes
https://greenteapress.com/wp/think-bayes/
https://habr.com/ru/post/510526/ bayes in python
http://web.ipac.caltech.edu/staff/fmasci/home/astro_refs/Science-2013-Efron.pdf
https://habrahabr.ru/post/337028/ video bayes deep ML
https://www.sanyamkapoor.com/machine-learning/the-beauty-of-bayesian-learning/
https://medium.freecodecamp.org/statistical-inference-showdown-the-frequentists-vs-the-bayesians-4c1c986f25de
https://www.analyticsvidhya.com/blog/2017/03/conditional-probability-bayes-theorem/
https://malobukov.dreamwidth.org/7960.html bayes
https://www.datascience.com/blog/introduction-to-bayesian-inference-learn-data-science-tutorials
https://news.ycombinator.com/item?id=18213117
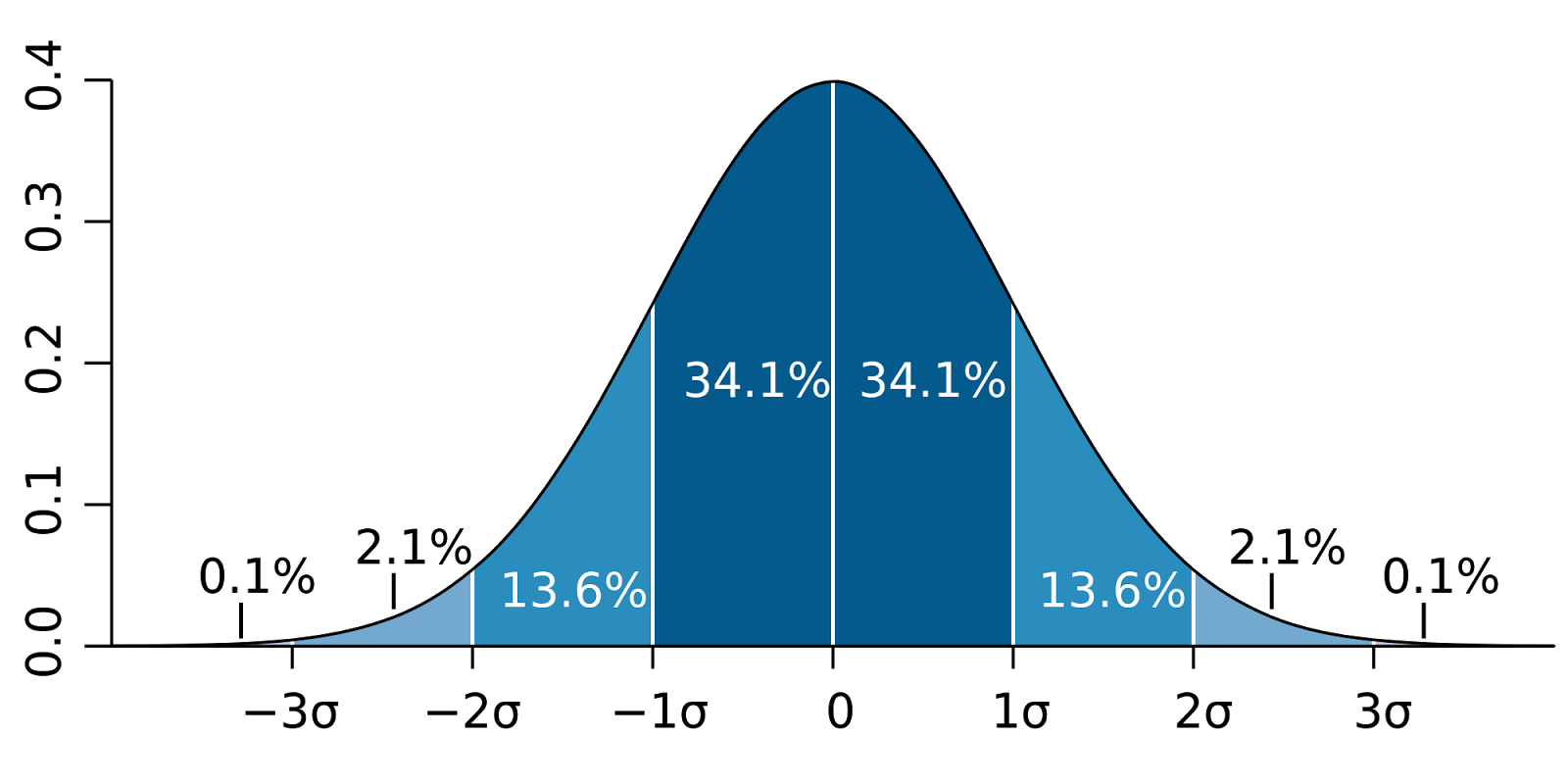
In the case of normally distributed data,
the three sigma rule means that roughly 1 in 22 observations will differ by twice the standard deviation or more from the mean,
and 1 in 370 will deviate by three times the standard deviation
Probability density function for normal disribution with sigma=1:
 https://www.dataquest.io/onboarding
https://www.dataquest.io/blog/learning-curves-machine-learning/
http://efavdb.com/
https://www.hardikp.com/
https://unsupervisedpandas.com/
https://www.zabaras.com/statisticalcomputing
https://www.dataquest.io/onboarding
https://www.dataquest.io/blog/learning-curves-machine-learning/
http://efavdb.com/
https://www.hardikp.com/
https://unsupervisedpandas.com/
https://www.zabaras.com/statisticalcomputing
Signal Processing
https://terpconnect.umd.edu/~toh/spectrum/
https://habr.com/post/358868/ Kalman filter
Machine Learning
Machine Learning code snippets
List of machine learning concepts
Tour-of-machine-learning-algorithms
Regression
https://developers.google.com/machine-learning/crash-course/
https://avva.livejournal.com/3074895.html#comments
https://robertheaton.com/2014/05/02/jaccard-similarity-and-minhash-for-winners/
http://efavdb.com/
https://talkery.io/conferences/507?pageNumber=1 PyData 2017 videos
www.wildml.com/2017/12/ai-and-deep-learning-in-2017-a-year-in-review/
https://habr.com/company/ods/blog/354944/
https://habrahabr.ru/company/itinvest/blog/262155/ TOP 10 ML algo
https://habrahabr.ru/company/cloud4y/blog/346968/
https://habrahabr.ru/post/347008/
https://habrahabr.ru/post/349048/ Autoencoders
https://habrahabr.ru/company/ods/blog/325422/ Feature extraction
https://github.com/featuretools/featuretools
https://www.youtube.com/watch?v=BfS2H1y6tzQ
https://www.youtube.com/watch?v=GsAVf3fn3yM&feature=youtu.be Artificial Intelligence with Python | Sequence Learning
https://www.youtube.com/watch?v=RLsKzkxWpK8
https://github.com/AxeldeRomblay/MLBox
https://habrahabr.ru/company/ods/blog/350440/ Jini index
Apple
https://github.com/apple/coremltools
https://attardi.org/pytorch-and-coreml
https://github.com/apple/turicreate
https://news.ycombinator.com/item?id=15406237 Apple CoreML
https://machinelearning.apple.com/2017/08/06/siri-voices.html
https://news.ycombinator.com/item?id=16364826
NLP
NLP
Speech recognition
https://habrahabr.ru/post/350222/
https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
https://news.ycombinator.com/item?id=16626374 word2vec
http://fast.ai
https://github.com/vicky002/AlgoWiki/blob/gh-pages/Machine-Learning/Sources.md
http://www.inference.vc/design-patterns/
https://notebooks.azure.com/jakevdp/libraries/PythonDataScienceHandbook
https://eli.thegreenplace.net/tag/machine-learning
http://course.fast.ai/
http://learningsys.org/nips17/assets/slides/dean-nips17.pdf TPU Google
R
https://radiant-rstats.github.io/docs/index.html
https://rattle.togaware.com/
Visualization and ML packages
https://veusz.github.io/
https://www.knime.com/
https://rapidminer.com/
https://sourceforge.net/projects/weka/
https://orange.biolab.si/
https://elki-project.github.io/
Matlab book
https://www.amazon.com/Exploratory-Analysis-Chapman-Computer-Science/dp/149877606X Exploratory Data Analysis with MATLAB, Third Edition
JavaScript
http://propelml.org/
https://news.ycombinator.com/item?id=16465105
Clustering
https://habrahabr.ru/post/164417/
https://www.youtube.com/watch?v=-_gIcc5_uHY
https://habrahabr.ru/post/322034/ DBSCAN
https://en.wikipedia.org/wiki/DBSCAN DBSCAN
https://towardsdatascience.com/a-gentle-introduction-to-hdbscan-and-density-based-clustering-5fd79329c1e8
https://mubaris.com/2017/10/01/kmeans-clustering-in-python/

 https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
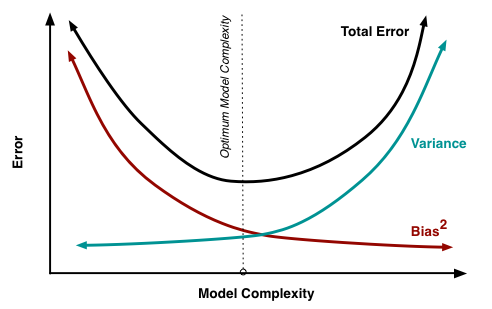
Bias is the difference between your model's expected predictions and the true values.
The error due to bias is taken as the difference between the expected (or average) prediction of our model and the correct value which we are trying to predict.
The error due to variance is taken as the variability of a model prediction for a given data point.
The variance is how much the predictions for a given point vary between different realizations of the model.
The small sample size is a source of variance. If we increased the sample size, the results would be more consistent.
The results still might be highly inaccurate due to our large sources of bias, but the variance of predictions will be reduced
Variance refers to your algorithm's sensitivity to specific sets of training data.
https://oneraynyday.github.io/ml/2017/08/08/Bias-Variance-Tradeoff/
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
Bias is the difference between your model's expected predictions and the true values.
The error due to bias is taken as the difference between the expected (or average) prediction of our model and the correct value which we are trying to predict.
The error due to variance is taken as the variability of a model prediction for a given data point.
The variance is how much the predictions for a given point vary between different realizations of the model.
The small sample size is a source of variance. If we increased the sample size, the results would be more consistent.
The results still might be highly inaccurate due to our large sources of bias, but the variance of predictions will be reduced
Variance refers to your algorithm's sensitivity to specific sets of training data.
https://oneraynyday.github.io/ml/2017/08/08/Bias-Variance-Tradeoff/
 High bias, low variance: model are consistent but inaccurate on averag
High variance, low bias: model are inconsistent but accurate on average
Low variance tends to be related to simpler atgorithms (regression, naive bayes, linear, parametric)
Low bias tends to be related to complex atgorithms (Decision tree, Near Neigbour, Non-parametric)
https://medium.com/@kevin_yang/simple-approximate-nearest-neighbors-in-python-with-annoy-and-lmdb-e8a701baf905
Regression algo can be regularized to reduce complexity
Decision tree can be pruned to reduce complexity
Too complex model -> overfitting
Too simple model -> underfitting
The Linear model does not fit the data very well and is therefore said to have a higher bias than the polynomial model.
Overfitting:
---------------
Our model doesn’t generalize well from our training data to unseen data.
Cross-validation is a powerful preventative measure against overfitting.
K-fold cross-validation: partition the the data into k subsets, called folds. Then, we iteratively train the algorithm on k-1 folds while using the remaining fold as the test set (called the “holdout fold”).
- Remove feature
- Regularization: you could prune a decision tree, use dropout on a neural network, or add a penalty parameter to the cost function in regression.
- Early stopping
When you’re training a learning algorithm iteratively, you can measure how well each iteration of the model performs.
Up until a certain number of iterations, new iterations improve the model. After that point, however, the model’s ability to generalize can weaken as it begins to overfit the training data.
Early stopping refers stopping the training process before the learner passes that point.
High bias, low variance: model are consistent but inaccurate on averag
High variance, low bias: model are inconsistent but accurate on average
Low variance tends to be related to simpler atgorithms (regression, naive bayes, linear, parametric)
Low bias tends to be related to complex atgorithms (Decision tree, Near Neigbour, Non-parametric)
https://medium.com/@kevin_yang/simple-approximate-nearest-neighbors-in-python-with-annoy-and-lmdb-e8a701baf905
Regression algo can be regularized to reduce complexity
Decision tree can be pruned to reduce complexity
Too complex model -> overfitting
Too simple model -> underfitting
The Linear model does not fit the data very well and is therefore said to have a higher bias than the polynomial model.
Overfitting:
---------------
Our model doesn’t generalize well from our training data to unseen data.
Cross-validation is a powerful preventative measure against overfitting.
K-fold cross-validation: partition the the data into k subsets, called folds. Then, we iteratively train the algorithm on k-1 folds while using the remaining fold as the test set (called the “holdout fold”).
- Remove feature
- Regularization: you could prune a decision tree, use dropout on a neural network, or add a penalty parameter to the cost function in regression.
- Early stopping
When you’re training a learning algorithm iteratively, you can measure how well each iteration of the model performs.
Up until a certain number of iterations, new iterations improve the model. After that point, however, the model’s ability to generalize can weaken as it begins to overfit the training data.
Early stopping refers stopping the training process before the learner passes that point.
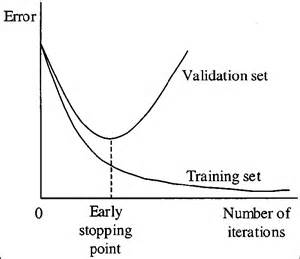 Underfitting
--------------
occurs when a model is too simple – informed by too few features or regularized too much – which makes it inflexible in learning from the dataset.
In both Machine Learning and Curve Fitting, you want to come up with a model that explains (fits) the data. However, the difference in the end goal is both subtle and profound.
In Curve Fitting, we have all the data available to us at the time of fitting the curve. We want to fit the curve as best as we can.
In Machine Learning, only a small set (the training set) of data is available at the time of training. We obviously want a model that fits the data well, but more importantly, we want the model to generalize to unseen data points
http://blog.dlib.net/2017/12/a-global-optimization-algorithm-worth.html
https://towardsdatascience.com/improving-vanilla-gradient-descent-f9d91031ab1d
Classification is forecasting the target class / category
Regression if forecasting a value.
Logistic regression - dependent variable is categorical.
https://www.analyticsvidhya.com/blog/2017/08/skilltest-logistic-regression/
Logistic function predict the corresponding target class.
Probability of result = logistic function:
y = 1 / ( 1 + exp(-f(x))) in range from 0 to 1.
if f(x) = 0 then y=0.5
if f(x) is big negative # then y=0
if f(x) is big positive # then y=1
f(x) = ax+b, here X is the input vector and A is a parameter vector
Goal is to find A.
The common method is Max likelehood (logarithm) criteria; the gradiend descend can be used
x - random outcomes
theta - parameter
L(theta| x) = P(x | theta)
Because the logarithm is a monotonically increasing function, the logarithm of a function achieves its maximum value at the same points as the function itself, and hence the log-likelihood can be used in place of the likelihood in maximum likelihood estimation
Regulariation: to decrease overfitting
https://habr.com/ru/post/456176/ . L1 and L2 Stohastic Gradient Descent
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization-How-does-it-solve-the-problem-of-overfitting-Which-regularizer-to-use-and-when
L2: Euclide
L1: producies many coefficients with zero values or very small values with few large coefficients
Bagging and other resampling techniques can be used to reduce the variance in model predictions.
In bagging (Bootstrap Aggregating), numerous replicates of the original data set are created using random selection with replacement.
Each derivative data set is then used to construct a new model and the models are gathered together into an ensemble.
To make a prediction, all of the models in the ensemble are polled and their results are averaged.
Bagging attempts to reduce the chance overfitting complex models.
It trains a large number of "strong" learners in parallel.
A strong learner is a model that's relatively unconstrained.
Bagging then combines all the strong learners together in order to "smooth out" their predictions.
Boosting attempts to improve the predictive flexibility of simple models.
It trains a large number of "weak" learners in sequence.
A weak learner is a constrained model (i.e. you could limit the max depth of each decision tree).
Each one in the sequence focuses on learning from the mistakes of the one before it.
Boosting then combines all the weak learners into a single strong learner.
While bagging and boosting are both ensemble methods, they approach the problem from opposite directions.
Bagging uses complex base models and tries to "smooth out" their predictions, while boosting uses simple base models and tries to "boost" their aggregate complexity.
https://www.analyticsvidhya.com/blog/2017/02/40-questions-to-ask-a-data-scientist-on-ensemble-modeling-techniques-skilltest-solution/
https://towardsdatascience.com/markov-chain-monte-carlo-in-python-44f7e609be98
https://habr.com/ru/company/piter/blog/491268/
Underfitting
--------------
occurs when a model is too simple – informed by too few features or regularized too much – which makes it inflexible in learning from the dataset.
In both Machine Learning and Curve Fitting, you want to come up with a model that explains (fits) the data. However, the difference in the end goal is both subtle and profound.
In Curve Fitting, we have all the data available to us at the time of fitting the curve. We want to fit the curve as best as we can.
In Machine Learning, only a small set (the training set) of data is available at the time of training. We obviously want a model that fits the data well, but more importantly, we want the model to generalize to unseen data points
http://blog.dlib.net/2017/12/a-global-optimization-algorithm-worth.html
https://towardsdatascience.com/improving-vanilla-gradient-descent-f9d91031ab1d
Classification is forecasting the target class / category
Regression if forecasting a value.
Logistic regression - dependent variable is categorical.
https://www.analyticsvidhya.com/blog/2017/08/skilltest-logistic-regression/
Logistic function predict the corresponding target class.
Probability of result = logistic function:
y = 1 / ( 1 + exp(-f(x))) in range from 0 to 1.
if f(x) = 0 then y=0.5
if f(x) is big negative # then y=0
if f(x) is big positive # then y=1
f(x) = ax+b, here X is the input vector and A is a parameter vector
Goal is to find A.
The common method is Max likelehood (logarithm) criteria; the gradiend descend can be used
x - random outcomes
theta - parameter
L(theta| x) = P(x | theta)
Because the logarithm is a monotonically increasing function, the logarithm of a function achieves its maximum value at the same points as the function itself, and hence the log-likelihood can be used in place of the likelihood in maximum likelihood estimation
Regulariation: to decrease overfitting
https://habr.com/ru/post/456176/ . L1 and L2 Stohastic Gradient Descent
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization-How-does-it-solve-the-problem-of-overfitting-Which-regularizer-to-use-and-when
L2: Euclide
L1: producies many coefficients with zero values or very small values with few large coefficients
Bagging and other resampling techniques can be used to reduce the variance in model predictions.
In bagging (Bootstrap Aggregating), numerous replicates of the original data set are created using random selection with replacement.
Each derivative data set is then used to construct a new model and the models are gathered together into an ensemble.
To make a prediction, all of the models in the ensemble are polled and their results are averaged.
Bagging attempts to reduce the chance overfitting complex models.
It trains a large number of "strong" learners in parallel.
A strong learner is a model that's relatively unconstrained.
Bagging then combines all the strong learners together in order to "smooth out" their predictions.
Boosting attempts to improve the predictive flexibility of simple models.
It trains a large number of "weak" learners in sequence.
A weak learner is a constrained model (i.e. you could limit the max depth of each decision tree).
Each one in the sequence focuses on learning from the mistakes of the one before it.
Boosting then combines all the weak learners into a single strong learner.
While bagging and boosting are both ensemble methods, they approach the problem from opposite directions.
Bagging uses complex base models and tries to "smooth out" their predictions, while boosting uses simple base models and tries to "boost" their aggregate complexity.
https://www.analyticsvidhya.com/blog/2017/02/40-questions-to-ask-a-data-scientist-on-ensemble-modeling-techniques-skilltest-solution/
https://towardsdatascience.com/markov-chain-monte-carlo-in-python-44f7e609be98
https://habr.com/ru/company/piter/blog/491268/
Decision Tree
https://github.com/Yorko/mlcourse.ai/blob/master/jupyter_russian/topic03_decision_trees_knn/topic3_trees_knn.ipynb
https://dataaspirant.com/2017/01/30/how-decision-tree-algorithm-works/
https://heartbeat.fritz.ai/introduction-to-decision-tree-learning-cd604f85e236
http://www.win-vector.com/blog/2017/01/why-do-decision-trees-work/
The primary challenge in the decision tree implementation is to identify which attributes do we need to consider as the root node and each level.
In decision tree algorithm calculating the nodes and forming the rules will happen using the information gain and Gini index.
Information Gain calculates the expected reduction in entropy due to sorting on the attribute.
Gini Index is a metric to measure how often a randomly chosen element would be incorrectly identified. It means an attribute with lower gini index should be preferred.
Random Forest
https://habr.com/ru/company/ruvds/blog/488342/
https://habr.com/ru/company/piter/blog/488362/
Random forest algorithm is a supervised classification algorithm.
Random forest algorithm can use both for classification and the regression kind of problems.
It works by training numerous decision trees each based on a different resampling of the original training data.
In Random Forests the bias of the full model is equivalent to the bias of a single decision tree (which itself has high variance).
By creating many of these trees, in effect a "forest", and then averaging them the variance of the final model can be greatly reduced over that of a single tree. In practice the only limitation on the size of the forest is computing time as an infinite number of trees could be trained without ever increasing bias and with a continual (if asymptotically declining) decrease in the variance.
https://victorzhou.com/blog/intro-to-random-forests/
http://dataaspirant.com/2017/05/22/random-forest-algorithm-machine-learing/
https://medium.com/@williamkoehrsen/random-forest-simple-explanation-377895a60d2d
https://medium.com/@williamkoehrsen/random-forest-in-python-24d0893d51c0
https://r4ds.had.co.nz/
https://news.ycombinator.com/item?id=19632052
Separate training and test sets
------------------------------------
Split the data into three sets — training (60%), validation (a.k.a development) (20%) and test (20%).
Use the training set to train different models, the validation set to select a model
and finally report performance on the test set.
- Trying appropriate algorithms (No Free Lunch)
- Fitting model parameters
- Tuning impactful hyperparameters
- Proper performance metrics
- Systematic cross-validation
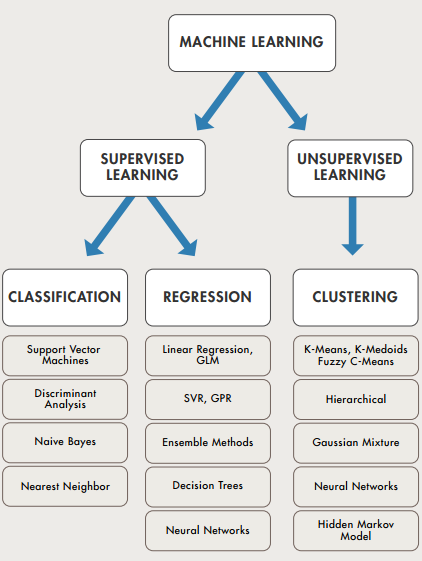 https://blog.statsbot.co/machine-learning-algorithms-183cc73197c
https://towardsdatascience.com/battle-of-the-deep-learning-frameworks-part-i-cff0e3841750
http://pbpython.com/categorical-encoding.html
https://www.kaggle.com/dansbecker/using-categorical-data-with-one-hot-encoding
https://github.com/onurakpolat/awesome-analytics
ML cheetsheets
Tensor Flow
ML DLIB C++
https://medium.com/@mngrwl/explained-simply-how-deepmind-taught-ai-to-play-video-games-9eb5f38c89ee
CoreML
ML blog
ML method
ML plan
MLOSS.org
distill.pub
### PCA
https://joellaity.com/2018/10/18/pca.html
PCA 1
PCA 2
Q & A
https://habrahabr.ru/company/newprolab/blog/350584/ t-SNE and UMAP
http://www.datatau.com/
https://www.bonaccorso.eu/
https://habrahabr.ru/company/oleg-bunin/blog/340184/ Architectures of NN
https://morfizm.livejournal.com/1136917.html BitFunnel
https://blog.statsbot.co/
http://rpubs.com/JDAHAN/172473
https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-algorithm-choice
https://elitedatascience.com/machine-learning-iteration
https://elitedatascience.com/dimensionality-reduction-algorithms
https://elitedatascience.com/machine-learning-algorithms
https://blog.statsbot.co/machine-learning-algorithms-183cc73197c
https://towardsdatascience.com/battle-of-the-deep-learning-frameworks-part-i-cff0e3841750
http://pbpython.com/categorical-encoding.html
https://www.kaggle.com/dansbecker/using-categorical-data-with-one-hot-encoding
https://github.com/onurakpolat/awesome-analytics
ML cheetsheets
Tensor Flow
ML DLIB C++
https://medium.com/@mngrwl/explained-simply-how-deepmind-taught-ai-to-play-video-games-9eb5f38c89ee
CoreML
ML blog
ML method
ML plan
MLOSS.org
distill.pub
### PCA
https://joellaity.com/2018/10/18/pca.html
PCA 1
PCA 2
Q & A
https://habrahabr.ru/company/newprolab/blog/350584/ t-SNE and UMAP
http://www.datatau.com/
https://www.bonaccorso.eu/
https://habrahabr.ru/company/oleg-bunin/blog/340184/ Architectures of NN
https://morfizm.livejournal.com/1136917.html BitFunnel
https://blog.statsbot.co/
http://rpubs.com/JDAHAN/172473
https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-algorithm-choice
https://elitedatascience.com/machine-learning-iteration
https://elitedatascience.com/dimensionality-reduction-algorithms
https://elitedatascience.com/machine-learning-algorithms